 SashaMaks
SashaMaks

 инфо
инфо инструменты
инструменты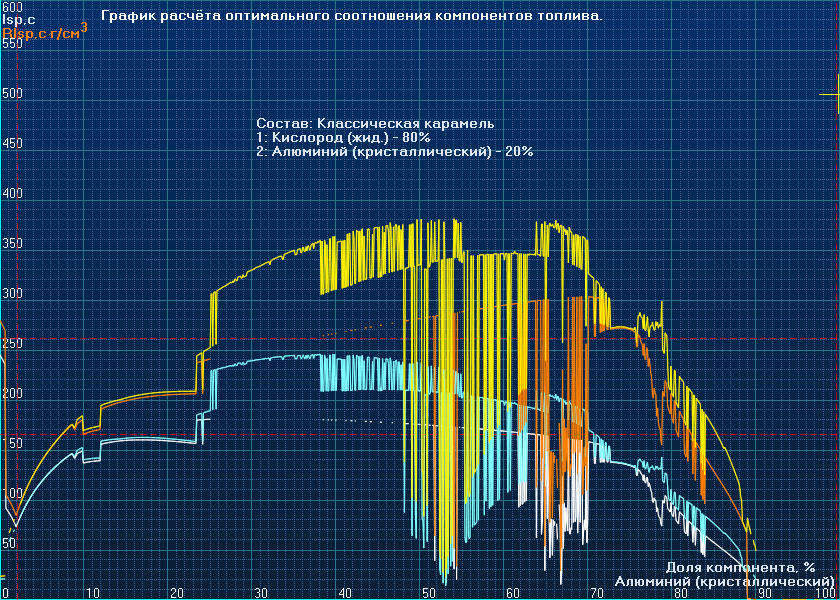
 Sharovar
Sharovar




 Реклама Google — средство выживания форумов :)
Реклама Google — средство выживания форумов :)
-
![[image]](https://www.balancer.ru/cache/sites/w/w/www.jamesyawn.com/titanium/2-29-04/128x128-crop/mold.jpg)
Твердые ракетные топлива карамельного типа ХII
Теги:
Pashok> Если рассматривать топлива без хлора в составе, с окислителями в виде динитрамида аммония и других бесхлорых окислителей... Если брать топлива на нитрате аммония
Приведи конкретный пример какого-нибудь такого топлива с реально достигнутым УИ на практике.
А лучше несколько примеров.
Приведи конкретный пример какого-нибудь такого топлива с реально достигнутым УИ на практике.
А лучше несколько примеров.



SashaMaks> Приведи конкретный пример какого-нибудь такого топлива с реально достигнутым УИ на практике.
SashaMaks> А лучше несколько примеров.
Открывай патенты, статьи. На самом деле информации куча.
SashaMaks> А лучше несколько примеров.
Открывай патенты, статьи. На самом деле информации куча.
Pashok> Открывай патенты, статьи. На самом деле информации куча.
И даже ссылки не приведёшь?
И даже ссылки не приведёшь?
Б.г.> Т.е. там, где расчётная функция недифференцируема в аналитическом представлении, в численном появляется большая "мёртвая зона", в этой зоне результаты вычисления будут недостоверны, даже если брать всякие "даблы" и "лонги".
Относительно малых изменений тоже всё понятно, по прежнему не понятно, как это относится к приближённому ручному счёту не на ЭВМ...
А так, вот ещё примерчик.
Было конечно круто глянуть алгоритм PROPEP на предмет его построения, но когда видишь такое. Короче нужно искать другой алгоритм расчёта равновесного состояния смеси. Тот, что в PROPEP не годится, слишком высока вероятность отказа в расчёте, где нужно будет делать до 1000000 таких вычислений только за одну итерацию.
Вообще это всё лечится, просто алгоритм PROPEP не совершенен в этом случае. Ведь в начале идёт вполне нормальная гладкая кривая...
Относительно малых изменений тоже всё понятно, по прежнему не понятно, как это относится к приближённому ручному счёту не на ЭВМ...
А так, вот ещё примерчик.
Было конечно круто глянуть алгоритм PROPEP на предмет его построения, но когда видишь такое. Короче нужно искать другой алгоритм расчёта равновесного состояния смеси. Тот, что в PROPEP не годится, слишком высока вероятность отказа в расчёте, где нужно будет делать до 1000000 таких вычислений только за одну итерацию.
Вообще это всё лечится, просто алгоритм PROPEP не совершенен в этом случае. Ведь в начале идёт вполне нормальная гладкая кривая...
Прикреплённые файлы:

Слово "жидкий" софт сократил до неполиткорректного, а более длинное "кристаллический" оставил как есть. Логику не осилил.
Sharovar> Слово "жидкий" софт сократил до неполиткорректного, а более длинное "кристаллический" оставил как есть. Логику не осилил.
И не надо её осиливать.
Попробуй для начала осилить перевод списка исходных компонентов с английского на русский.
И не надо её осиливать.
Попробуй для начала осилить перевод списка исходных компонентов с английского на русский.
Pashok> Открывай патенты, статьи. На самом деле информации куча.
Там всё расчётный УИ в CEA.
Кстати, я могу подключить термодинамическую базу данных из CEA в PROPEP, всего-то переназначить переменные и три формулы переписать...
И ещё для расчёта к-фазы размер сопла имеет значение. С увеличением длины сопла увеличивается время теплового взаимодействия твёрдых частиц с газом => полнее идёт передача тепла от к-фазы в газ => потери УИ от к-фазы ослабевают приближаясь к идеальным расчётным значениям без учёта к-фазы.
Там всё расчётный УИ в CEA.
Кстати, я могу подключить термодинамическую базу данных из CEA в PROPEP, всего-то переназначить переменные и три формулы переписать...
И ещё для расчёта к-фазы размер сопла имеет значение. С увеличением длины сопла увеличивается время теплового взаимодействия твёрдых частиц с газом => полнее идёт передача тепла от к-фазы в газ => потери УИ от к-фазы ослабевают приближаясь к идеальным расчётным значениям без учёта к-фазы.

SashaMaks> И ещё для расчёта к-фазы размер сопла имеет значение.
Имеет, да, чем меньше критика, тем больше потери.
SashaMaks> С увеличением длины сопла увеличивается время теплового взаимодействия твёрдых частиц с газом => полнее идёт передача тепла от к-фазы в газ => потери УИ от к-фазы ослабевают приближаясь к идеальным расчётным значениям без учёта к-фазы.
Нет, нет, не так. Во-первых, даже в самом длинном сопле время нахождения пренебрежимо мало, и составляет, скажем, для двигателя "Шаттла" пару-тройку миллисекунд. Даже для газовой фазы термодинамическое равновесие установиться не успевает, что уж говорить о теплообмене между к-фазой и газом.
Во-вторых, даже если бы этот подвод тепла и существовал, он бы вероятнее снижал скорость, чем повышал её, как снижала бы её сужающаяся труба. В дозвуковой части подвод энергии полезен, в сверхзвуковой - бесполезен, если не вреден.
Ты не задумывался, почему сопла РДТТ чаще всего простые конические, в то время, как сопла ЖРД, даже первых ступеней, обычно профилированные?
Нет, не всё так просто с к-фазой в выхлопе...
Имеет, да, чем меньше критика, тем больше потери.
SashaMaks> С увеличением длины сопла увеличивается время теплового взаимодействия твёрдых частиц с газом => полнее идёт передача тепла от к-фазы в газ => потери УИ от к-фазы ослабевают приближаясь к идеальным расчётным значениям без учёта к-фазы.
Нет, нет, не так. Во-первых, даже в самом длинном сопле время нахождения пренебрежимо мало, и составляет, скажем, для двигателя "Шаттла" пару-тройку миллисекунд. Даже для газовой фазы термодинамическое равновесие установиться не успевает, что уж говорить о теплообмене между к-фазой и газом.
Во-вторых, даже если бы этот подвод тепла и существовал, он бы вероятнее снижал скорость, чем повышал её, как снижала бы её сужающаяся труба. В дозвуковой части подвод энергии полезен, в сверхзвуковой - бесполезен, если не вреден.
Ты не задумывался, почему сопла РДТТ чаще всего простые конические, в то время, как сопла ЖРД, даже первых ступеней, обычно профилированные?
Нет, не всё так просто с к-фазой в выхлопе...

Б.г.> Ты не задумывался, почему сопла РДТТ чаще всего простые конические, в то время, как сопла ЖРД, даже первых ступеней, обычно профилированные?
Может и задумывался, но ты всё равно расскажи, может я это потом на расчёт переложу.
Б.г.> Нет, не всё так просто с к-фазой в выхлопе...
Я и не говорю, что просто. Это пока для начала. Правда продолжение будет не скоро, скорее всего гораздо раньше будет информация с практики.
Может и задумывался, но ты всё равно расскажи, может я это потом на расчёт переложу.
Б.г.> Нет, не всё так просто с к-фазой в выхлопе...
Я и не говорю, что просто. Это пока для начала. Правда продолжение будет не скоро, скорее всего гораздо раньше будет информация с практики.
Б.г.> Имеет, да, чем меньше критика, тем больше потери.
Б.г.> Ты не задумывался, почему сопла РДТТ чаще всего простые конические, в то время, как сопла ЖРД, даже первых ступеней, обычно профилированные?
Я не однократно агитировал за то что не нужно в моторы с маленьким соплом пихать по 16% алюминия и Саше предлагал сопло сделать чисто коническое чтобы К фаза не налипала. А с другой стороны, можно представить себе длину не профилированного сопла для ЖРД на ~200атм.")
Да и изготавливаются, охлаждаются они по разному.
Б.г.> Ты не задумывался, почему сопла РДТТ чаще всего простые конические, в то время, как сопла ЖРД, даже первых ступеней, обычно профилированные?
Я не однократно агитировал за то что не нужно в моторы с маленьким соплом пихать по 16% алюминия и Саше предлагал сопло сделать чисто коническое чтобы К фаза не налипала. А с другой стороны, можно представить себе длину не профилированного сопла для ЖРД на ~200атм.
Да и изготавливаются, охлаждаются они по разному.
Pashok>> Открывай патенты, статьи. На самом деле информации куча.
SashaMaks> Там всё расчётный УИ в CEA.
SashaMaks> Кстати, я могу подключить термодинамическую базу данных из CEA в PROPEP, всего-то переназначить переменные и три формулы переписать...
Ну пусть так. Пусть там ноль практики и одна теория во всех учебниках статьях и патентах. Давай попробуем тогда разобраться на всем известном практическом примере. Топливо для ускорителей шаттла. Там 16% алюминия, окислитель хлорсодержащий. По твоим прикидкам сколько там К-фазы из сопла вылетает?
SashaMaks> Там всё расчётный УИ в CEA.
SashaMaks> Кстати, я могу подключить термодинамическую базу данных из CEA в PROPEP, всего-то переназначить переменные и три формулы переписать...
Ну пусть так. Пусть там ноль практики и одна теория во всех учебниках статьях и патентах. Давай попробуем тогда разобраться на всем известном практическом примере. Топливо для ускорителей шаттла. Там 16% алюминия, окислитель хлорсодержащий. По твоим прикидкам сколько там К-фазы из сопла вылетает?
Это сообщение редактировалось 30.11.2013 в 13:48
LEVSHA> ...и Саше предлагал сопло сделать чисто коническое чтобы К фаза не налипала.
Да, вроде ничего не налипает. Да, длинное сопло из керамики => хана массовому совершенству.
Вот, кстати, последняя форма (уже полностью готовая к первой формовке) для критического диаметра 11мм:
Немного длиннее получилась, чем предшествующая на 12мм с тем же габаритом.
Да, вроде ничего не налипает. Да, длинное сопло из керамики => хана массовому совершенству.
Вот, кстати, последняя форма (уже полностью готовая к первой формовке) для критического диаметра 11мм:
Немного длиннее получилась, чем предшествующая на 12мм с тем же габаритом.
Прикреплённые файлы:
Pashok> Пусть там ноль практики и одна теория во всех учебниках статьях и патентах.
Поищи сам, я уже устал. Я буду очень признателен.
Pashok> По твоим прикидкам сколько там К-фазы из сопла вылетает?
Много. Но это обсуждение бессмысленно. Всё, что ты хочешь сказать, я уже понял. Ты тоже не веришь в мои расчёты. Вроде бы на этом можно закончить уже?
Поищи сам, я уже устал. Я буду очень признателен.
Pashok> По твоим прикидкам сколько там К-фазы из сопла вылетает?
Много. Но это обсуждение бессмысленно. Всё, что ты хочешь сказать, я уже понял. Ты тоже не веришь в мои расчёты. Вроде бы на этом можно закончить уже?
SashaMaks> Много. Но это обсуждение бессмысленно. Всё, что ты хочешь сказать, я уже понял. Ты тоже не веришь в мои расчёты. Вроде бы на этом можно закончить уже?
Я не неверю в расчеты. Просто считаю, что на данный момент все учесть сделав их очень точными крайне затруднительно, только и всего.
Я не неверю в расчеты. Просто считаю, что на данный момент все учесть сделав их очень точными крайне затруднительно, только и всего.
Serge77> А какое у тебя образование? Кажется высшее техническое? Какое именно? Неужели вам не читали по поводу погрешности инженерных расчётов?
Побывал сегодня на кафедре высшей математики ЯГТУ.
Без долго вступления.
Пытался объяснить суть вопроса, на это ушло примерно 20мин. Т.е. преподаватель изначально не понял причём тут высшая математика: "Мы не занимаются погрешностями". Хорошо, я понял, что представившись, как человек с производства, переиначил, что увлекаюсь и ничего за этим не стоит, а так же перешёл к рассмотрению задачи чисто в теоретическом виде расчёта на ЭВМ.
По поводу правильности или достоверности этих записей:
Serge77> Я не совсем об этом спрашивал, но пусть будет 5%.
Serge77> Тогда вот это
Serge77> "НН-Сорбит (65-35) без серы
Serge77> Удельный импульс топлива, с 121,7539
Serge77> НН-Сорбит-S (62,4-33,6-4) с серой
Serge77> Удельный импульс топлива, с 122,1219"
Serge77> правильно писать
Serge77> "НН-Сорбит (65-35) без серы
Serge77> Удельный импульс топлива, с 122 ±6
Serge77> НН-Сорбит-S (62,4-33,6-4) с серой
Serge77> Удельный импульс топлива, с 122 ±6"
Serge77> Значит, никаких выводов, что чего больше, сделать нельзя.
Прозвучала фраза: "Ни той ни другой записи верить нельзя, так как не указаны доверительные интервалы погрешностей." Что фактически означало, хотите верьте расчёту на ЭВМ, хотите нет. Далее, раскрывая смысл погрешности именно численного расчёта некой модели на ЭВМ такого уровня прозвучало сравнение данного метода вычисления на ЭВМ с лопатой, которой можно ровно всё вскопать или наоборот всё испохабить. Собственно "колбаса" на последних представленных мной графиках алгоритма PROPEP это доказывает. По поводу альтернативных алгоритмов расчёта равновесного состояния смесей, он предложил подойти в понедельник к ещё одному спецу, занимающемуся именно этой тематикой (в том числе и методами статистической обработки данных с численных моделей) Каневскому Игорю Марковичу, что детально понять, как же всё таки считается погрешность для численных расчётов на ЭВМ.
А пока, он сказал, чтобы иметь хоть какое представление о достоверности полученных цифрах с модели, необходимо иметь доверительную вероятность выпадение того или иного результата, т.е. вероятность. Эту вероятность можно просчитать (для чего есть специальные программы тестирования), делая выборку из всех дельта интервалов погрешностей исходных данных и пересчитывая, в результате чего получается некая функция вероятностного распределения расчётного результата, по которой можно будет определить достоверность получения цифры в указанном интервале погрешности. И тут же оговорился, что такие методы так же имеют свои погрешности, и в целом задача сложная и неоднозначная.
Побывал сегодня на кафедре высшей математики ЯГТУ.
Без долго вступления.
Пытался объяснить суть вопроса, на это ушло примерно 20мин. Т.е. преподаватель изначально не понял причём тут высшая математика: "Мы не занимаются погрешностями". Хорошо, я понял, что представившись, как человек с производства, переиначил, что увлекаюсь и ничего за этим не стоит, а так же перешёл к рассмотрению задачи чисто в теоретическом виде расчёта на ЭВМ.
По поводу правильности или достоверности этих записей:
Serge77> Я не совсем об этом спрашивал, но пусть будет 5%.
Serge77> Тогда вот это
Serge77> "НН-Сорбит (65-35) без серы
Serge77> Удельный импульс топлива, с 121,7539
Serge77> НН-Сорбит-S (62,4-33,6-4) с серой
Serge77> Удельный импульс топлива, с 122,1219"
Serge77> правильно писать
Serge77> "НН-Сорбит (65-35) без серы
Serge77> Удельный импульс топлива, с 122 ±6
Serge77> НН-Сорбит-S (62,4-33,6-4) с серой
Serge77> Удельный импульс топлива, с 122 ±6"
Serge77> Значит, никаких выводов, что чего больше, сделать нельзя.
Прозвучала фраза: "Ни той ни другой записи верить нельзя, так как не указаны доверительные интервалы погрешностей." Что фактически означало, хотите верьте расчёту на ЭВМ, хотите нет. Далее, раскрывая смысл погрешности именно численного расчёта некой модели на ЭВМ такого уровня прозвучало сравнение данного метода вычисления на ЭВМ с лопатой, которой можно ровно всё вскопать или наоборот всё испохабить. Собственно "колбаса" на последних представленных мной графиках алгоритма PROPEP это доказывает. По поводу альтернативных алгоритмов расчёта равновесного состояния смесей, он предложил подойти в понедельник к ещё одному спецу, занимающемуся именно этой тематикой (в том числе и методами статистической обработки данных с численных моделей) Каневскому Игорю Марковичу, что детально понять, как же всё таки считается погрешность для численных расчётов на ЭВМ.
А пока, он сказал, чтобы иметь хоть какое представление о достоверности полученных цифрах с модели, необходимо иметь доверительную вероятность выпадение того или иного результата, т.е. вероятность. Эту вероятность можно просчитать (для чего есть специальные программы тестирования), делая выборку из всех дельта интервалов погрешностей исходных данных и пересчитывая, в результате чего получается некая функция вероятностного распределения расчётного результата, по которой можно будет определить достоверность получения цифры в указанном интервале погрешности. И тут же оговорился, что такие методы так же имеют свои погрешности, и в целом задача сложная и неоднозначная.
Да, нужен доверительный интервал, обычно он берётся как 95%.
Я же писал, что использовал упрощённый метод, который учили в школе. И не предлагал им пользоваться. Есть "настоящие" методы определения погрешности, вот их я и предлагал узнать.
Ты спроси, можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами.
Я же писал, что использовал упрощённый метод, который учили в школе. И не предлагал им пользоваться. Есть "настоящие" методы определения погрешности, вот их я и предлагал узнать.
Ты спроси, можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами.

Serge77> Ты спроси, можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами.
Уже спрашивал, на что и был получен ответ о любой возможной вычислительной погрешности "лопаты" (вроде недоглядок деления на ноль и пр.) и, что нужно считать вероятность.
Иными словами если будет цифра, к примеру, 121,25 ±0,01 с вероятностью 80%, то опять же найдутся те кого такая вероятность устроит, а кого нет.
Или же
121,2543546 ±0,0000001 с вероятностью 40%. И снова хотите верьте, хотите нет.
П.С. Я этими расчётами точно заниматься не буду, мне и без них хватает работы с расчётами...
Уже спрашивал, на что и был получен ответ о любой возможной вычислительной погрешности "лопаты" (вроде недоглядок деления на ноль и пр.) и, что нужно считать вероятность.
Иными словами если будет цифра, к примеру, 121,25 ±0,01 с вероятностью 80%, то опять же найдутся те кого такая вероятность устроит, а кого нет.
Или же
121,2543546 ±0,0000001 с вероятностью 40%. И снова хотите верьте, хотите нет.
П.С. Я этими расчётами точно заниматься не буду, мне и без них хватает работы с расчётами...
SashaMaks> П.С. Я этими расчётами точно заниматься не буду, мне и без них хватает работы с расчётами...
Что вообще значит посчитать вероятность.
Если на входе 400 исходных данных со своими погрешностями - это означает 400-н-мерное пространство, где возможна тьма тьмущая комбинаций выборок, даже самые упрощенные алгоритмы в этом случае могут быть необъективны, на что собственно он и оговорился. А последовательно перебирать всё это пространство, даже с шагом 1/10 от каждого интервала, так можно и машину повесить до конца дней своих и не дождаться никакого результата.
Что вообще значит посчитать вероятность.
Если на входе 400 исходных данных со своими погрешностями - это означает 400-н-мерное пространство, где возможна тьма тьмущая комбинаций выборок, даже самые упрощенные алгоритмы в этом случае могут быть необъективны, на что собственно он и оговорился. А последовательно перебирать всё это пространство, даже с шагом 1/10 от каждого интервала, так можно и машину повесить до конца дней своих и не дождаться никакого результата.
SashaMaks> Вот, кстати, последняя форма...
Нижняя форма явно лучше особенно форма дивергентной части. А вот конвергенту в зоне входа в критику я бы исправил и за счет длинны критики сделал бы более плавной как на рисунке снизу.
Нижняя форма явно лучше особенно форма дивергентной части. А вот конвергенту в зоне входа в критику я бы исправил и за счет длинны критики сделал бы более плавной как на рисунке снизу.
Прикреплённые файлы:
Serge77>> Ты спроси, можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами.
SashaMaks> Уже спрашивал, на что и был получен ответ о любой возможной вычислительной погрешности "лопаты" (вроде недоглядок деления на ноль и пр.) и, что нужно считать вероятность.
Это ответ о том, что и при точных исходных данных можно получить результат с плохой точностью. Т.е. испортить всегда можно, это ясно.
Вопрос в другом - можно ли какими-то расчётами, пусть даже 64-, хоть 164-битными, получить точность лучше, чем в исходных данных.
Задай вопрос буквально, точной цитатой"можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами"
SashaMaks> Уже спрашивал, на что и был получен ответ о любой возможной вычислительной погрешности "лопаты" (вроде недоглядок деления на ноль и пр.) и, что нужно считать вероятность.
Это ответ о том, что и при точных исходных данных можно получить результат с плохой точностью. Т.е. испортить всегда можно, это ясно.
Вопрос в другом - можно ли какими-то расчётами, пусть даже 64-, хоть 164-битными, получить точность лучше, чем в исходных данных.
Задай вопрос буквально, точной цитатой"можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами"
Serge77> Задай вопрос буквально, точной цитатой"можно ли имея исходные данные с тремя значащими цифрами, получить результат с семью значащими цифрами"
Хорошо.
Понимаю куда ты клонишь, напомню то, что я в первую очередь написал ещё перед расчётом:
"Полгода назад я получил первые теоретические подтверждения того, что серой карамель не испортить, как минимум, и даже можно улучшить."
Если раскрыть эту фразу в виде математической записи в цифрах получится:
"НН-Сорбит (65-35) без серы
Удельный импульс топлива, с 122 ±6
НН-Сорбит-S (62,4-33,6-4) с серой
Удельный импульс топлива, с 122 ±6"
Хорошо.
Понимаю куда ты клонишь, напомню то, что я в первую очередь написал ещё перед расчётом:
"Полгода назад я получил первые теоретические подтверждения того, что серой карамель не испортить, как минимум, и даже можно улучшить."
Если раскрыть эту фразу в виде математической записи в цифрах получится:
"НН-Сорбит (65-35) без серы
Удельный импульс топлива, с 122 ±6
НН-Сорбит-S (62,4-33,6-4) с серой
Удельный импульс топлива, с 122 ±6"
SashaMaks> "...и даже можно улучшить."
Даже - значило, что есть такая выборка при которой наблюдается максимум.
Естественно, что значения в расчётах, взятых в пределах одной выборки на ЭВМ сравниваются с вычислительной погрешность. И будет то, что я написал:
"НН-Сорбит (65-35) без серы
Удельный импульс топлива, с 121,7539
НН-Сорбит-S (62,4-33,6-4) с серой
Удельный импульс топлива, с 122,1219"
Но народ воспринимает подобные записи, здесь с единственной вероятностью 100%, видимо это такой психологический эффект производит - хотя бы раз упомянуть даже о единственной вероятности существования такого решения)))
Даже - значило, что есть такая выборка при которой наблюдается максимум.
Естественно, что значения в расчётах, взятых в пределах одной выборки на ЭВМ сравниваются с вычислительной погрешность. И будет то, что я написал:
"НН-Сорбит (65-35) без серы
Удельный импульс топлива, с 121,7539
НН-Сорбит-S (62,4-33,6-4) с серой
Удельный импульс топлива, с 122,1219"
Но народ воспринимает подобные записи, здесь с единственной вероятностью 100%, видимо это такой психологический эффект производит - хотя бы раз упомянуть даже о единственной вероятности существования такого решения)))
LEVSHA> Нижняя форма явно лучше особенно форма дивергентной части. А вот конвергенту в зоне входа в критику я бы исправил и за счет длинны критики сделал бы более плавной как на рисунке снизу.
Тут не всё так просто, в конструкции сопла есть ещё массивный слой ТЗП и контур профиля будет совсем другим. Поэтому пытаться тут словить блох - бесполезное занятие. А ведь почти весь этот слой ТЗП выгорает к концу работы двигателя или, как минимум половина.
Тут не всё так просто, в конструкции сопла есть ещё массивный слой ТЗП и контур профиля будет совсем другим. Поэтому пытаться тут словить блох - бесполезное занятие. А ведь почти весь этот слой ТЗП выгорает к концу работы двигателя или, как минимум половина.
Прикреплённые файлы:
Это сообщение редактировалось 30.11.2013 в 21:39

не удержался, на тему вероятности и результатов ее применения
Задаем вопрос: «Какова вероятность того что вы выйдете на улицу и встретите ДИНОЗАВРА?»
Мужчина: -Ну 1 к миллиарду
Женщина: -50 на 50
- Почему?
Женщина: - Или встречу, или не встречу…
Задаем вопрос: «Какова вероятность того что вы выйдете на улицу и встретите ДИНОЗАВРА?»
Мужчина: -Ну 1 к миллиарду
Женщина: -50 на 50
- Почему?
Женщина: - Или встречу, или не встречу…
Реклама Google — средство выживания форумов :)
 Xan
Xan

SashaMaks> "НН-Сорбит (65-35) без серы
SashaMaks> Удельный импульс топлива, с 121,7539
SashaMaks> НН-Сорбит-S (62,4-33,6-4) с серой
SashaMaks> Удельный импульс топлива, с 122,1219"
Как тебе удалось такое насчитать?
Почему мне Пропеп говорит иное?
SashaMaks> Удельный импульс топлива, с 121,7539
SashaMaks> НН-Сорбит-S (62,4-33,6-4) с серой
SashaMaks> Удельный импульс топлива, с 122,1219"
Как тебе удалось такое насчитать?
Почему мне Пропеп говорит иное?
Copyright © Balancer 1997..2022
Создано 10.11.2008
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
Создано 10.11.2008
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
