-
![[image]](https://www.balancer.ru/cache/sites/org/ha/habrastorage/getpro/habr/post_images/cf2/e41/6ea/128x128-crop/cf2e416ea047ad95ea7cf05bca7dd783.png)
Разговоры о компьютерах
Теги:
 GOGI
GOGI

подскажите, кто знает. Есть .net приложение. Мне в нем надо одну строку поменять (укоротить). Как найти где располагается то число, которое задает длину этой строки? В хекс-редакторе я саму строку нашел, могу её редактировать, но как уменьшить её размер?


 инфо
инфо инструменты
инструменты Mishka
Mishka

GOGI> подскажите, кто знает. Есть .net приложение. Мне в нем надо одну строку поменять (укоротить). Как найти где располагается то число, которое задает длину этой строки? В хекс-редакторе я саму строку нашел, могу её редактировать, но как уменьшить её размер?
Совсем простого ответа нет, т.к. внутрях строки могут храниться, как:
1. Последовательнойсть байтов, которая оканчивается 0.
2. Последовательность слов по схеме/коду UTF-16, которая тоже может оканчиваться 0.
3. Как объект типа String, внутри которого храниться длина и массив в UTF-16.
UTF-16 — это код, который кодирует символы переменными последовательностями. В зависимости от того, где символ находится, он представляется либо 2 байтами, либо 4.
Внутрях объекта класса String есть массив (array), который заканчивается null character, чтобы можно было передавать напрямую в функции С стиля. Но, там есть длина отдельно и сам объект класса String не рассматривается, как null character terminated.
Поэтому для С стиля строк — надо просто всатдалить null character в то место, где ты хочешь, чтобы она кончалась (раньше). А вот для String — надо и в массиве править, и в счётчике. Только там два числа — длина строки и длина массива. Я не помню где что. Это надо спрашивать тех, кто на C# пишет активно.
Вот про устройство класса String — https://msdn.microsoft.com/en-us/library/system.string.aspx
Это пример — Reference Source
У этого мужика очень хороший разбор по устройству объектов класса String — http://csharpindepth.com/Articles/General/Strings.aspx
Совсем простого ответа нет, т.к. внутрях строки могут храниться, как:
1. Последовательнойсть байтов, которая оканчивается 0.
2. Последовательность слов по схеме/коду UTF-16, которая тоже может оканчиваться 0.
3. Как объект типа String, внутри которого храниться длина и массив в UTF-16.
UTF-16 — это код, который кодирует символы переменными последовательностями. В зависимости от того, где символ находится, он представляется либо 2 байтами, либо 4.
Внутрях объекта класса String есть массив (array), который заканчивается null character, чтобы можно было передавать напрямую в функции С стиля. Но, там есть длина отдельно и сам объект класса String не рассматривается, как null character terminated.
Поэтому для С стиля строк — надо просто всатдалить null character в то место, где ты хочешь, чтобы она кончалась (раньше). А вот для String — надо и в массиве править, и в счётчике. Только там два числа — длина строки и длина массива. Я не помню где что. Это надо спрашивать тех, кто на C# пишет активно.
Вот про устройство класса String — https://msdn.microsoft.com/en-us/library/system.string.aspx
Это пример — Reference Source
У этого мужика очень хороший разбор по устройству объектов класса String — http://csharpindepth.com/Articles/General/Strings.aspx
 Meskiukas
Meskiukas

Не знаю сюда ли?  Люди, помогите беде. Диск Е, винчестер на 200 Гб почему-то закрылся. Точнее показывает его как инородный. WindowsXP. Пытался импортировать много раз, всё выдаёт такую фиговину. Хотелось бы открыть диск не потеряв информацию.
Люди, помогите беде. Диск Е, винчестер на 200 Гб почему-то закрылся. Точнее показывает его как инородный. WindowsXP. Пытался импортировать много раз, всё выдаёт такую фиговину. Хотелось бы открыть диск не потеряв информацию.
Люди, помогите беде. Диск Е, винчестер на 200 Гб почему-то закрылся. Точнее показывает его как инородный. WindowsXP. Пытался импортировать много раз, всё выдаёт такую фиговину. Хотелось бы открыть диск не потеряв информацию.
Прикреплённые файлы:
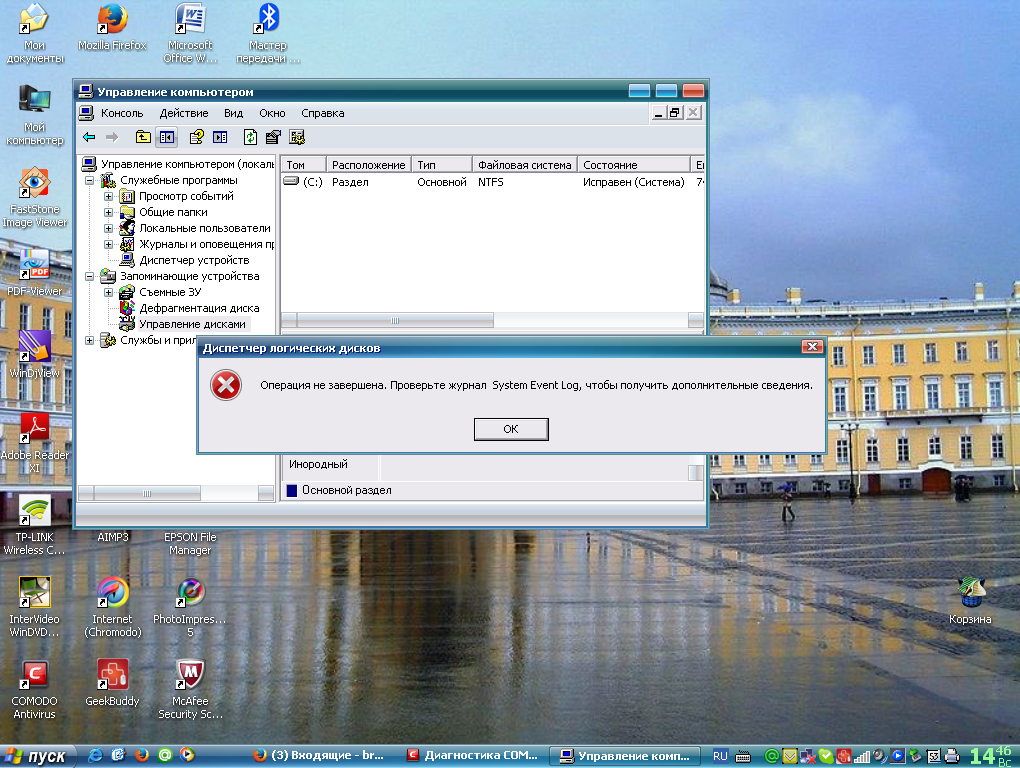
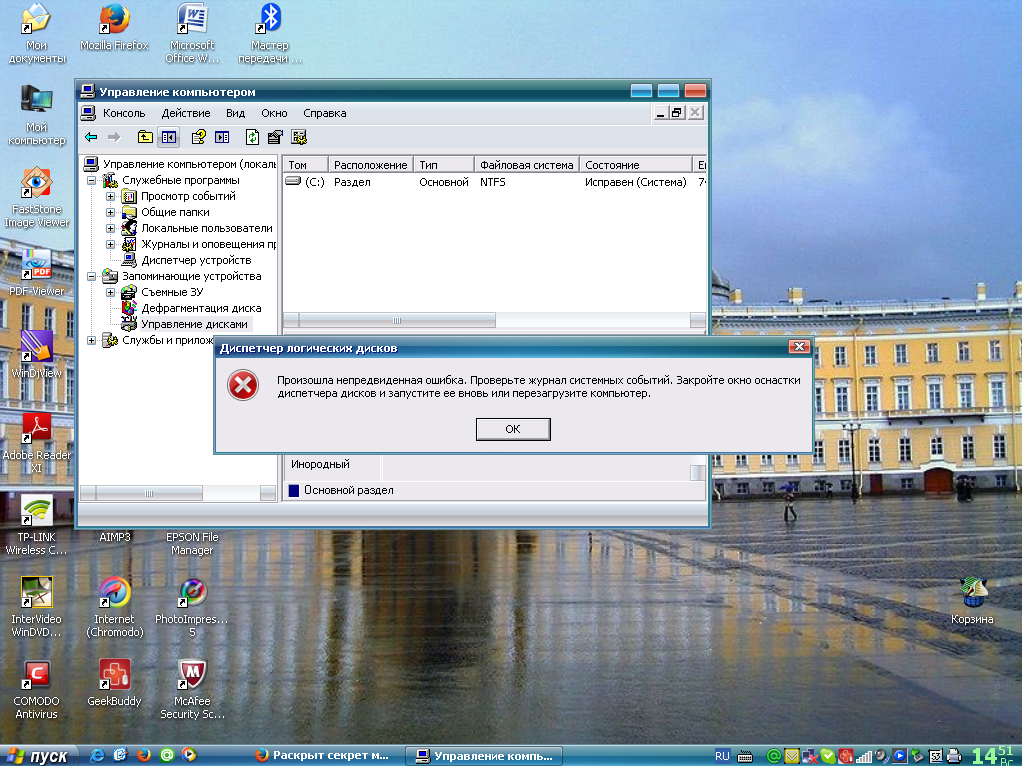
Mishka> Совсем простого ответа нет
Да уж, пришлось декомпилировать, редактировать и перекомпилировать. Хорошо что приложение не обфусцировано было, а то бы я хрен разобрался.
Да уж, пришлось декомпилировать, редактировать и перекомпилировать. Хорошо что приложение не обфусцировано было, а то бы я хрен разобрался.
 ssb
ssb

Meskiukas> Не знаю сюда ли? Люди, помогите беде. Диск Е, винчестер на 200 Гб почему-то закрылся. Точнее показывает его как инородный. WindowsXP. Пытался импортировать много раз, всё выдаёт такую фиговину. Хотелось бы открыть диск не потеряв информацию.
Виден ли диск на заведомо исправной (linux/unix) машине? Если нет, то — в сервис (т к скорее всего имеем случай 1 (а), см. ниже)
Иначе можно применить следующий алгоритм (для опытных):
Метод извлечения инфы с умирающих хардов "вручную"
(успешно применён автором за последние 13 лет бесчисленное число раз)
Вся работы выполняется при помощи linux с загрузочной флешки и/или перетыканием диска в исправную linux-машину.
1. Шаг первый: необходимо проверить хард на функционирование вообще и на наличие/отсутствие битых (reallocated / uncorrectab / pending) секторов.
Необходимую инфу выдаёт команда
Варианты действий по результатам:
(а) Диск не определился ядром, определился с нулевым размером, или команда smartctl выдала ошибку — небходимо хирургическое вмешательство специалистом с железячным оборудованием в виде отвёртки, программатора, запасных плат и прочих донорских органов — вморг сервис.
(б) смарт-инфа получена, число битых секторов десятки/сотня — диск "сыпется" и откажет в ближайшие дни-часы-минуты, необходим незамедлительный перенос инфы при помощи специальной программы (типа dd_rescue), которая сольёт образ за одно обращение и не будет "пилить" повреждённые сектора.
(в) число битых секторов единицы-первые десятки — диск сыпется и его дни сочтены, но при переносе данных можно позволить себе вальяжность.
(г) секторов 1-2-несколько — их можно занулить, убедиться в том, что они отремаппились (превратились из pending/offline_uncorrectable в reallocated), проверить файловую систему, и продолжить использование диска, с учётом того, что его дни, опять-таки, сочтены.
2. Шаг второй (случаи б/в):
Опыт показал, что в запущенных случаях требуется применение "спецсредств", так как стандратные программы "запиливают" диск до смерти при первой же попытке слить данные. Я пользуюсь слегка захаченной древней версией (1.14) dd_rescue dd_rescue . Про новые ничего сказать не могу, пока не применял.
Кроме того, крайне желательно использовать захаченное ядро linux во избежание пятикратной езды по больному месту:
Команда для слива образа диска:
И, наконец, вариант (г) требует особого рассмотрения, но я его опущу для краткости.
Люди, помогите беде. Диск Е, винчестер на 200 Гб почему-то закрылся. Точнее показывает его как инородный. WindowsXP. Пытался импортировать много раз, всё выдаёт такую фиговину. Хотелось бы открыть диск не потеряв информацию.Виден ли диск на заведомо исправной (linux/unix) машине? Если нет, то — в сервис (т к скорее всего имеем случай 1 (а), см. ниже)
Иначе можно применить следующий алгоритм (для опытных):
Метод извлечения инфы с умирающих хардов "вручную"
(успешно применён автором за последние 13 лет бесчисленное число раз)
Вся работы выполняется при помощи linux с загрузочной флешки и/или перетыканием диска в исправную linux-машину.
1. Шаг первый: необходимо проверить хард на функционирование вообще и на наличие/отсутствие битых (reallocated / uncorrectab / pending) секторов.
Необходимую инфу выдаёт команда
code text
- smartctl -a /dev/sdx
Варианты действий по результатам:
(а) Диск не определился ядром, определился с нулевым размером, или команда smartctl выдала ошибку — небходимо хирургическое вмешательство специалистом с железячным оборудованием в виде отвёртки, программатора, запасных плат и прочих донорских органов — в
(б) смарт-инфа получена, число битых секторов десятки/сотня — диск "сыпется" и откажет в ближайшие дни-часы-минуты, необходим незамедлительный перенос инфы при помощи специальной программы (типа dd_rescue), которая сольёт образ за одно обращение и не будет "пилить" повреждённые сектора.
(в) число битых секторов единицы-первые десятки — диск сыпется и его дни сочтены, но при переносе данных можно позволить себе вальяжность.
(г) секторов 1-2-несколько — их можно занулить, убедиться в том, что они отремаппились (превратились из pending/offline_uncorrectable в reallocated), проверить файловую систему, и продолжить использование диска, с учётом того, что его дни, опять-таки, сочтены.
2. Шаг второй (случаи б/в):
Опыт показал, что в запущенных случаях требуется применение "спецсредств", так как стандратные программы "запиливают" диск до смерти при первой же попытке слить данные. Я пользуюсь слегка захаченной древней версией (1.14) dd_rescue dd_rescue . Про новые ничего сказать не могу, пока не применял.
Кроме того, крайне желательно использовать захаченное ядро linux во избежание пятикратной езды по больному месту:
code text
- ---
- drivers/scsi/sd.h | 2 +-
- 1 file changed, 1 insertion(+), 1 deletion(-)
- Index: linux/drivers/scsi/sd.h
- ===================================================================
- --- linux.orig/drivers/scsi/sd.h
- +++ linux/drivers/scsi/sd.h
- @@ -23,7 +23,7 @@
- /*
- * Number of allowed retries
- */
- -#define SD_MAX_RETRIES 5
- +#define SD_MAX_RETRIES 0
- #define SD_PASSTHROUGH_RETRIES 1
- /*
Команда для слива образа диска:
code text
- dd_rescue -A -b 524288 -B 512 -y 0 -d /dev/sdx disk.img
- # по желанию добавить опции -o badblocks -l log
- # опция -A обязательна, иначе образ получется непригодным для монтирования
И, наконец, вариант (г) требует особого рассмотрения, но я его опущу для краткости.

GOGI> Помогите с wget.
можно им, а можно

Там не надо придумывать скрипты, достаточно уровень выкачивания указать, всё будет слито. В твоем случае выставляешь уровень 2 - и запускаешь закачку.
Впрочем, если нужны более точные настройки, то их там тоже есть")
можно им, а можно
MetaProducts Offline Explorer / Offline Browser (Часть 3) - [1] :: Программы :: Компьютерный форум Ru.Board
Компьютерный форум Ru.Board // forum.ru-board.comТам не надо придумывать скрипты, достаточно уровень выкачивания указать, всё будет слито. В твоем случае выставляешь уровень 2 - и запускаешь закачку.
Впрочем, если нужны более точные настройки, то их там тоже есть
VAS63> 1. Подскажите простенький бесплатный видеоредактор. Интересует только возможность обрезать/склеивать куски видео
Mp4 joiner, mp4 splitter
микроутилиты меньше метра весом, работают шустро, инсталла по памяти не требовали. Сам юзаю.
Mp4 joiner, mp4 splitter
микроутилиты меньше метра весом, работают шустро, инсталла по памяти не требовали. Сам юзаю.
ssb> Метод извлечения инфы с умирающих хардов "вручную"
а можно поподробнее? Не совсем понятно, по ссылке - уже модифицированная версия или надо самостоятельно что-то сделать?
Указанный код "захаченного ядра" куда пихать?
Никсовая флешка любая сойдет, или есть какие-то отличия в оболочке или врсии или еще хз чему (напр, числу подгруженных дров)
а можно поподробнее? Не совсем понятно, по ссылке - уже модифицированная версия или надо самостоятельно что-то сделать?
Указанный код "захаченного ядра" куда пихать?
Никсовая флешка любая сойдет, или есть какие-то отличия в оболочке или врсии или еще хз чему (напр, числу подгруженных дров)
ssb>> Метод извлечения инфы с умирающих хардов "вручную"
Bredonosec> ... Не совсем понятно, по ссылке - уже модифицированная версия или надо самостоятельно что-то сделать?
По ссылке оригинальная утилита. Я пользовался древней версией оной, с небольшой (но, ЕМНИС, несущественной модификацией).
Bredonosec> Указанный код "захаченного ядра" куда пихать?
Пропатчить исходники и пересобрать.
Bredonosec> Никсовая флешка любая сойдет, или есть какие-то отличия в оболочке или врсии или еще хз чему (напр, числу подгруженных дров)
Сойдёт любая. Но!!! При использовании немодифицированного ядра больные сектора будут пять раз перечитываться, а без корректного использования dd_rescue (т е, без O_DIRECT) — на каждый битый сектор будет 8 обращений из pagecache (размер страницы в pagecache 4096 / размер аппаратного сектора 512), итого по 5x8 == 40 повторов.
Bredonosec> а можно поподробнее?
На следующей неделе (когда время будет), и если ещё будет нужно, могу расписать с подробностями, примерами и пояснениями...
Bredonosec> ... Не совсем понятно, по ссылке - уже модифицированная версия или надо самостоятельно что-то сделать?
По ссылке оригинальная утилита. Я пользовался древней версией оной, с небольшой (но, ЕМНИС, несущественной модификацией).
Bredonosec> Указанный код "захаченного ядра" куда пихать?
Пропатчить исходники и пересобрать.
Bredonosec> Никсовая флешка любая сойдет, или есть какие-то отличия в оболочке или врсии или еще хз чему (напр, числу подгруженных дров)
Сойдёт любая. Но!!! При использовании немодифицированного ядра больные сектора будут пять раз перечитываться, а без корректного использования dd_rescue (т е, без O_DIRECT) — на каждый битый сектор будет 8 обращений из pagecache (размер страницы в pagecache 4096 / размер аппаратного сектора 512), итого по 5x8 == 40 повторов.
Bredonosec> а можно поподробнее?
На следующей неделе (когда время будет), и если ещё будет нужно, могу расписать с подробностями, примерами и пояснениями...
ssb> На следующей неделе (когда время будет), и если ещё будет нужно, могу расписать с подробностями, примерами и пояснениями...
был бы благодарен, иногда требуется.
Хоть всякие примочки с резервированием особо важного добра используются, но иногда спрашивают на тему вытащить что-то из умершего или умирающего зверька.
был бы благодарен, иногда требуется.
Хоть всякие примочки с резервированием особо важного добра используются, но иногда спрашивают на тему вытащить что-то из умершего или умирающего зверька.
ssb>> На следующей неделе (когда время будет), и если ещё будет нужно, могу расписать с подробностями, примерами и пояснениями...
Bredonosec> был бы благодарен, иногда требуется.
Bredonosec> Хоть всякие примочки с резервированием особо важного добра используются, но иногда спрашивают на тему вытащить что-то из умершего или умирающего зверька.
Итак, попробую хоть как-то [частично] выполнить обещание, несмотря на перманентный writer's block
Я не буду рассматривать все возможные случаи, иначе придётся написать статью на десяток страниц.
На мой взгляд, наиболее универсальной и предпочтительной процедурой[1] при обнаружении битых секторов aka бэдблоков является следующая
(0). Заготовить инструмент:
а) исправный диск с достаточным свободным местом для сохранения образа данных
б) загрузочный диск (любой: hdd/cd/флешка) с софтом[2], а именно: пропатченным[3] ядром linux и программой dd_rescue, а также утилитами smartmontools.
(1). Загрузиться в linux, убедиться через dmesg в том, что оба диска, ремонтируемый и свободный подключились. Назовём для определённости ниже их sda и sdb соответственно.
(2). Выполнить короткий селфтест:
smartctl -t short /dev/sda
Он займёт пару минут.
(3). После окончания теста: проверить SMART информацию с подозреваемого:
smartctl -a /dev/sda
Выведенная информация разбита на секции, вначале общая инфа про диск, затем параметры, затем значения счётчиков, лог ошибок и лог селфтеста.
Процедура спасения данных необходима в случае ненулевого значения следующих счётчиков:
Или же в случае завершения короткого теста с ошибкой, например:
# 1 Short offline Completed: read failure 10% 4009 252793598
В обоих случаях наверняка будет заполнен лог ошибок диска. Есть исключение, когда лог ошибок заполнен, но диск исправен и ремонта не требует — это плохой кабель или контакт разъёма. В этом случае в логе ошибок наблюдается приблизит. следующее:
84 51 00 c7 33 c1 42 Error: ICRC, ABRT at LBA = 0x02c133c7 = 46216135 + код типа команды "READ FPDMA QUEUED". Ремонт заключается в разборке компа, замене ide/sata кабеля и аккуратной и тщательной сборке.
Также из вывода smartctl определяем физический размер сектора для команды dd_rescue ниже, это или 512 (у старых) или 4096 (у новых дисков).
(4). В случае подтверждения повреждения поверхности диска требуется сохранение данных. Сначала монтируем свободный раздел командой типа:
mount /dev/sdb1 /mnt
Затем запускам собственно сохранение данных командой dd_rescue из пакета ddrescue (sic):
nohup dd_rescue -A -b 524288 -B РАЗМЕРСЕКТОРА -y 0 -d /dev/sda /mnt/disk.img &. Наблюдаем за процессом:
tail -f nohup.out.
Обращаю внимание что критически важны опции -A, -B и -d: опция -A указывает dd_rescue записывать нули в в образ вместо непрочитанных секторов. Иначе полученный образ будет непригоден для извлечения из него данных. Опция -B указывает корректный размер физического сектора, а опция -d указывает dd_rescue вести чтение непосредственно с диска, а не через page cache. Иначе этим самым page cache будет автоматически выполнено множество повторов в случае ошибок, что резко снижает шансы на успех.
Также можно добавить опции к dd_rescue: -l /mnt/disk.log -b /mnt/disk.bb для сохранения лога и списка обнаруженных при чтении бэдов. Это полезно в безнадёжных случаях.
(5). Процедура завершена, отмонтируем диск с сохранёнными данными: umount /mnt. Выключаем комп, отсоединяем пострадавший диск и кладём на полку. На всякий пожарный можно сделать вторую копию с образа, и дальнейшую работу по извлечению данных вести с ней. Как работать с образом диска отдельно расписывать не буду — можно или записать его целиком на другой диск требуемого объёма, либо подмонтировать напрямую через -o loop. Желательно перед этим сделать fsck прямо на образе.
[1] Данная процедура оптимальна в случае сильно посыпавшихся дисков, которые уже невозможно прочитать обычными средствами. В случае пары битых секторов это перебор, а в случае полного отказа диска данный метод конечно уже не поможет. Ну и на всякий случай уточню, что на SSD этот метод не испытывался и для них не предназначался.
Для ntfs мною написана более совершенная утилитка для снятия образа диска, которая читает только задействованные файловой системой сектора. Для использования широкой публикой я эту тулзень не публиковал, ежели кому очень понадобится — обращайтесь тут.
[2] Рекомендую pld rescue как неоднократно опробованный, но годится, наверно, любой загрузочный линух с необходимыми ddrescue и smartmontools.
[3] Патч для linux, резко повышает шансы на успех операции в запущенных случаях, применим ко всем версиям. Как патчить/компилировать/изготовить загрузочный диск с собственным ядром не указываю — слишком много писать, извините. )
[4] На усмотрение пользователя: сохранять можно не весь диск, а только один раздел с ценной инфой.
Bredonosec> был бы благодарен, иногда требуется.
Bredonosec> Хоть всякие примочки с резервированием особо важного добра используются, но иногда спрашивают на тему вытащить что-то из умершего или умирающего зверька.
Итак, попробую хоть как-то [частично] выполнить обещание, несмотря на перманентный writer's block
Я не буду рассматривать все возможные случаи, иначе придётся написать статью на десяток страниц.
На мой взгляд, наиболее универсальной и предпочтительной процедурой[1] при обнаружении битых секторов aka бэдблоков является следующая
последовательность действий:
(0). Заготовить инструмент:
а) исправный диск с достаточным свободным местом для сохранения образа данных
б) загрузочный диск (любой: hdd/cd/флешка) с софтом[2], а именно: пропатченным[3] ядром linux и программой dd_rescue, а также утилитами smartmontools.
(1). Загрузиться в linux, убедиться через dmesg в том, что оба диска, ремонтируемый и свободный подключились. Назовём для определённости ниже их sda и sdb соответственно.
(2). Выполнить короткий селфтест:
smartctl -t short /dev/sda
Он займёт пару минут.
(3). После окончания теста: проверить SMART информацию с подозреваемого:
smartctl -a /dev/sda
Выведенная информация разбита на секции, вначале общая инфа про диск, затем параметры, затем значения счётчиков, лог ошибок и лог селфтеста.
Процедура спасения данных необходима в случае ненулевого значения следующих счётчиков:
code text
- Reallocated_Sector_Ct
- Reallocated_Event_Count
- Current_Pending_Sector
- Offline_Uncorrectable
Или же в случае завершения короткого теста с ошибкой, например:
# 1 Short offline Completed: read failure 10% 4009 252793598
В обоих случаях наверняка будет заполнен лог ошибок диска. Есть исключение, когда лог ошибок заполнен, но диск исправен и ремонта не требует — это плохой кабель или контакт разъёма. В этом случае в логе ошибок наблюдается приблизит. следующее:
84 51 00 c7 33 c1 42 Error: ICRC, ABRT at LBA = 0x02c133c7 = 46216135 + код типа команды "READ FPDMA QUEUED". Ремонт заключается в разборке компа, замене ide/sata кабеля и аккуратной и тщательной сборке.
Также из вывода smartctl определяем физический размер сектора для команды dd_rescue ниже, это или 512 (у старых) или 4096 (у новых дисков).
(4). В случае подтверждения повреждения поверхности диска требуется сохранение данных. Сначала монтируем свободный раздел командой типа:
mount /dev/sdb1 /mnt
Затем запускам собственно сохранение данных командой dd_rescue из пакета ddrescue (sic):
nohup dd_rescue -A -b 524288 -B РАЗМЕРСЕКТОРА -y 0 -d /dev/sda /mnt/disk.img &. Наблюдаем за процессом:
tail -f nohup.out.
Обращаю внимание что критически важны опции -A, -B и -d: опция -A указывает dd_rescue записывать нули в в образ вместо непрочитанных секторов. Иначе полученный образ будет непригоден для извлечения из него данных. Опция -B указывает корректный размер физического сектора, а опция -d указывает dd_rescue вести чтение непосредственно с диска, а не через page cache. Иначе этим самым page cache будет автоматически выполнено множество повторов в случае ошибок, что резко снижает шансы на успех.
Также можно добавить опции к dd_rescue: -l /mnt/disk.log -b /mnt/disk.bb для сохранения лога и списка обнаруженных при чтении бэдов. Это полезно в безнадёжных случаях.
(5). Процедура завершена, отмонтируем диск с сохранёнными данными: umount /mnt. Выключаем комп, отсоединяем пострадавший диск и кладём на полку. На всякий пожарный можно сделать вторую копию с образа, и дальнейшую работу по извлечению данных вести с ней. Как работать с образом диска отдельно расписывать не буду — можно или записать его целиком на другой диск требуемого объёма, либо подмонтировать напрямую через -o loop. Желательно перед этим сделать fsck прямо на образе.
Примечания:
[1] Данная процедура оптимальна в случае сильно посыпавшихся дисков, которые уже невозможно прочитать обычными средствами. В случае пары битых секторов это перебор, а в случае полного отказа диска данный метод конечно уже не поможет. Ну и на всякий случай уточню, что на SSD этот метод не испытывался и для них не предназначался.
Для ntfs мною написана более совершенная утилитка для снятия образа диска, которая читает только задействованные файловой системой сектора. Для использования широкой публикой я эту тулзень не публиковал, ежели кому очень понадобится — обращайтесь тут.
[2] Рекомендую pld rescue как неоднократно опробованный, но годится, наверно, любой загрузочный линух с необходимыми ddrescue и smartmontools.
[3] Патч для linux, резко повышает шансы на успех операции в запущенных случаях, применим ко всем версиям. Как патчить/компилировать/изготовить загрузочный диск с собственным ядром не указываю — слишком много писать, извините. )
code text
- ---
- drivers/scsi/sd.h | 2 +-
- 1 file changed, 1 insertion(+), 1 deletion(-)
- Index: linux/drivers/scsi/sd.h
- ===================================================================
- --- linux.orig/drivers/scsi/sd.h
- +++ linux/drivers/scsi/sd.h
- @@ -23,7 +23,7 @@
- /*
- * Number of allowed retries
- */
- -#define SD_MAX_RETRIES 5
- +#define SD_MAX_RETRIES 0
- #define SD_PASSTHROUGH_RETRIES 1
- /*
[4] На усмотрение пользователя: сохранять можно не весь диск, а только один раздел с ценной инфой.
не подскажете какую-нибудь прогу для создания резервных копий?
т.е., чтобы она по расписанию раз в день скидывала в архив изменения, произошедшие с файлами, раз в месяц делала полный бэкап. Ни или по какому другому алгоритму этим занималась, но чтобы организовать хоть какой-то подход к сохранению информации.
т.е., чтобы она по расписанию раз в день скидывала в архив изменения, произошедшие с файлами, раз в месяц делала полный бэкап. Ни или по какому другому алгоритму этим занималась, но чтобы организовать хоть какой-то подход к сохранению информации.

В Windows 10 есть встроенное средство для бэкапов. Вполне нормально работает. Насколько я помню, оно и в семерке тоже самое.
Главное не перепутать, в десятке есть еще средство для создания образов дисков, вот оно нихрена нормально не работает.
Для документов и прочей мелочи лучше всего Dropbox. Много раз выручал.
Главное не перепутать, в десятке есть еще средство для создания образов дисков, вот оно нихрена нормально не работает.
Для документов и прочей мелочи лучше всего Dropbox. Много раз выручал.
GOGI> В Windows 10 есть встроенное средство для бэкапов.
а где его можно пошшупать (найти, в смысле)?
а где его можно пошшупать (найти, в смысле)?
 digger
digger
В.Н.> не подскажете какую-нибудь прогу для создания резервных копий?
В.Н.> т.е., чтобы она по расписанию раз в день скидывала в архив изменения, произошедшие с файлами
Что есть файлы и сколько их? У меня семейные фотки, например, на 2-х компьютерах плюс на ДВД, можно еще пользоваться облаком, но "я им не верю".Сорсы копируются на работе руками в директорию для каждой версии и тоже в 3 места, но их намного меньше.Дома диск C с Windows сохранен в имидж и хранится на этом и на другом компьютере перекрестно, так что его можно накатать за 10 минут, так же было на прежней работе. Сейчас на работе - никак, у них жесткие требования IT, и если будет беда, придется переустанавливаться.
В.Н.> т.е., чтобы она по расписанию раз в день скидывала в архив изменения, произошедшие с файлами
Что есть файлы и сколько их? У меня семейные фотки, например, на 2-х компьютерах плюс на ДВД, можно еще пользоваться облаком, но "я им не верю".Сорсы копируются на работе руками в директорию для каждой версии и тоже в 3 места, но их намного меньше.Дома диск C с Windows сохранен в имидж и хранится на этом и на другом компьютере перекрестно, так что его можно накатать за 10 минут, так же было на прежней работе. Сейчас на работе - никак, у них жесткие требования IT, и если будет беда, придется переустанавливаться.


В.Н.> не подскажете какую-нибудь прогу для создания резервных копий?
В.Н.> т.е., чтобы она по расписанию раз в день скидывала в архив изменения, произошедшие с файлами, раз в месяц делала полный бэкап. Ни или по какому другому алгоритму этим занималась, но чтобы организовать хоть какой-то подход к сохранению информации.
Так любая нормальная система контроля версий, Mercurial, например. Только скрипт для автоматизации сделать, да и всё. Я так вообще ручками запускаю, без скриптов.
Собственно, рекомендую как раз Mercurial, ибо он целиком на Питоне, и соответственно мультиплатформенный. Есть синхронизация по сети и через переносные носители, да вообще через всё, что имеет файловую систему.
В.Н.> т.е., чтобы она по расписанию раз в день скидывала в архив изменения, произошедшие с файлами, раз в месяц делала полный бэкап. Ни или по какому другому алгоритму этим занималась, но чтобы организовать хоть какой-то подход к сохранению информации.
Так любая нормальная система контроля версий, Mercurial, например. Только скрипт для автоматизации сделать, да и всё. Я так вообще ручками запускаю, без скриптов.
Собственно, рекомендую как раз Mercurial, ибо он целиком на Питоне, и соответственно мультиплатформенный. Есть синхронизация по сети и через переносные носители, да вообще через всё, что имеет файловую систему.

В.Н.>> не подскажете какую-нибудь прогу для создания резервных копий?
Sandro> Собственно, рекомендую как раз Mercurial, ибо он целиком на Питоне, и соответственно мультиплатформенный. Есть синхронизация по сети и через переносные носители, да вообще через всё, что имеет файловую систему.
Вот уже в который раз убеждаюсь, насколько Гоги более человечный человек, чем некоторые более другие форумчане
ему задали вопрос, он дал простой ответ - в винде посмотри. А вот более другие сразу начинают какие-то непонятные слова говорить - Питон, скрипты, мультиплатформенный, панимаишь. Эх, никакого человеческого отношения.
вопрос из-за чего возник - я внезапно осознал, что на работе вся-вся информация (проекты, запросы заказчиков, рабочая документация, всё в общем) хранится на одном винте и винт этот стоит в рабочем компьютере, на котором также выполняют текущую работу. И если (или правильнее сказать "когда"?) этот винт накроется, то всё производство встанет колом и я даже не могу сказать, какие титанические усилия придётся приложить, чтобы работа возобновилась. будет просто полная опа.
Дело усложняется тем, что никакого айтишника у нас нет. Я, конечно обратился к руководству с вопросом - "а может нам какой-никакой NAS приобресть - ну там RAIDы всякие, аддитивные бэкапы опять-же" (слова-то такие я знаю).
Понимание, вроде, встретил, но меня поставили в неловкое положение вопросом - "если мы эту коробку купим, то ты сможешь всё это настроить"?
Тут я технично ушел в сторону, но, чую этот вопрос неизбежно возникнет. Хотелось-бы понять - стоит мне соваться в это дело, или как-бы хуже не наделал
Sandro> Собственно, рекомендую как раз Mercurial, ибо он целиком на Питоне, и соответственно мультиплатформенный. Есть синхронизация по сети и через переносные носители, да вообще через всё, что имеет файловую систему.
Вот уже в который раз убеждаюсь, насколько Гоги более человечный человек, чем некоторые более другие форумчане
ему задали вопрос, он дал простой ответ - в винде посмотри. А вот более другие сразу начинают какие-то непонятные слова говорить - Питон, скрипты, мультиплатформенный, панимаишь. Эх, никакого человеческого отношения.
вопрос из-за чего возник - я внезапно осознал, что на работе вся-вся информация (проекты, запросы заказчиков, рабочая документация, всё в общем) хранится на одном винте и винт этот стоит в рабочем компьютере, на котором также выполняют текущую работу. И если (или правильнее сказать "когда"?) этот винт накроется, то всё производство встанет колом и я даже не могу сказать, какие титанические усилия придётся приложить, чтобы работа возобновилась. будет просто полная опа.
Дело усложняется тем, что никакого айтишника у нас нет. Я, конечно обратился к руководству с вопросом - "а может нам какой-никакой NAS приобресть - ну там RAIDы всякие, аддитивные бэкапы опять-же" (слова-то такие я знаю).
Понимание, вроде, встретил, но меня поставили в неловкое положение вопросом - "если мы эту коробку купим, то ты сможешь всё это настроить"?
Тут я технично ушел в сторону, но, чую этот вопрос неизбежно возникнет. Хотелось-бы понять - стоит мне соваться в это дело, или как-бы хуже не наделал

Sandro> Так любая нормальная система контроля версий, Mercurial, например. Только скрипт для автоматизации сделать
Можно воспользоваться SparkleShare.

Тот же Dropbox, только под Git.
Можно воспользоваться SparkleShare.
SparkleShare - Self hosted, instant, secure file sync
SparkleShare creates a special folder on your computer. You can add remotely hosted folders (or "projects") to this folder. These projects will be automatically kept in sync with both the host and all of your peers when someone adds, removes or edits a file. SparkleShare was made to cover certain use cases, but doesn't handle every scenario well. To help you decide if SparkleShare is right for you, here's a few examples of what it does well and less well with smiley faces: For more information on usecases, read the wiki. // Дальше — www.sparkleshare.orgТот же Dropbox, только под Git.
В.Н.> вопрос из-за чего возник - я внезапно осознал, что на работе вся-вся информация (проекты, запросы заказчиков, рабочая документация, всё в общем) хранится на одном винте и винт этот стоит в рабочем компьютере, на котором также выполняют текущую работу.
Или придет рэнсом и всё зашифрует.Если это фирма, пинайте IT, это их работа. Или избегайте их ,а то заформализуют всё так,что невозможно будет работать.У нас ничего не делается, несмотря на многочисленность IT, я бэкапю всё вручную.
Или придет рэнсом и всё зашифрует.Если это фирма, пинайте IT, это их работа. Или избегайте их ,а то заформализуют всё так,что невозможно будет работать.У нас ничего не делается, несмотря на многочисленность IT, я бэкапю всё вручную.
В.Н.> а где его можно пошшупать (найти, в смысле)?
Панель управления - архивация и восстановление
Панель управления - архивация и восстановление

В.Н.>> вопрос из-за чего возник - я внезапно осознал, что на работе вся-вся информация . . .
digger> У нас ничего не делается, несмотря на многочисленность IT, я бэкапю всё вручную.
Хосподи, мы же (контора наша) на этом фоне монстры-перестраховщики.
1. Все обязаны сливать наработанное за день на сетевой ресурс подразделения.
2. 90% всех сетевых ресурсов (подразделенческие, общие, архив(ы)) в реплике.
3. Они же, локально на серверах с локальными теневыми копиями (2 раза в сутки обновляемыми) - типичный "срок хранения" 10-20 суток)
4. Особо критичные для работы системы ресурсы в трёх репликах.
5. Ежеквартально архив (и ещё по мелочи) сливается на отдельный диск и в несгораемый шкаф).
6. БД - отдельная песня, там своя система, но, собираемся на что-то подобное, как с файловыми ресурсами, переводить.
Был случай (нас, ITшников конечно не красящий) - внезапно выяснилось, что один из файловых серверов вылетел, и находится в таком состоянии уже около месяца. Но, всё работало, ничего не потеряли.
Отлегло от сердца, таки, мы не рабыздолбаи - рабыздолбаи не мы
digger> У нас ничего не делается, несмотря на многочисленность IT, я бэкапю всё вручную.
Хосподи, мы же (контора наша) на этом фоне монстры-перестраховщики.
1. Все обязаны сливать наработанное за день на сетевой ресурс подразделения.
2. 90% всех сетевых ресурсов (подразделенческие, общие, архив(ы)) в реплике.
3. Они же, локально на серверах с локальными теневыми копиями (2 раза в сутки обновляемыми) - типичный "срок хранения" 10-20 суток)
4. Особо критичные для работы системы ресурсы в трёх репликах.
5. Ежеквартально архив (и ещё по мелочи) сливается на отдельный диск и в несгораемый шкаф).
6. БД - отдельная песня, там своя система, но, собираемся на что-то подобное, как с файловыми ресурсами, переводить.
Был случай (нас, ITшников конечно не красящий) - внезапно выяснилось, что один из файловых серверов вылетел, и находится в таком состоянии уже около месяца. Но, всё работало, ничего не потеряли.
Отлегло от сердца, таки, мы не ра
В.Н.>> а где его можно пошшупать (найти, в смысле)?
GOGI> Панель управления - архивация и восстановление
После того, как у меня пару раз виндовый бэкап отказался восстанавливаться - я ему не верю. Совсем.
GOGI> Панель управления - архивация и восстановление
После того, как у меня пару раз виндовый бэкап отказался восстанавливаться - я ему не верю. Совсем.
 Unix
Unix

В.Н.> Понимание, вроде, встретил, но меня поставили в неловкое положение вопросом - "если мы эту коробку купим, то ты сможешь всё это настроить"?
Наймите человека который настроит. Объясни руководству что сколько бы это не стоило - это дешевле тупо закрытия бизнеса :-\
В.Н.> Тут я технично ушел в сторону, но, чую этот вопрос неизбежно возникнет. Хотелось-бы понять - стоит мне соваться в это дело, или как-бы хуже не наделал
Может начать с экстренной покупки внешнего диска WD? Они сразу с простейшим бэкап-софтом для винды идут. А потом в уже более спокойной обстановке обдумать нормальную схему бэкапа.
Наймите человека который настроит. Объясни руководству что сколько бы это не стоило - это дешевле тупо закрытия бизнеса :-\
В.Н.> Тут я технично ушел в сторону, но, чую этот вопрос неизбежно возникнет. Хотелось-бы понять - стоит мне соваться в это дело, или как-бы хуже не наделал
Может начать с экстренной покупки внешнего диска WD? Они сразу с простейшим бэкап-софтом для винды идут. А потом в уже более спокойной обстановке обдумать нормальную схему бэкапа.

Вопрос от чайника:
Хочу подключить вторым монитором телевизор. На ТВ есть VGA вход, на компе два выхода VGA на материнке и на видеокарте. К видеокарте подключен монитор. Можно ли подключить VGA-кабелем с материнки телевизор, не будет конфликта?
Хочу подключить вторым монитором телевизор. На ТВ есть VGA вход, на компе два выхода VGA на материнке и на видеокарте. К видеокарте подключен монитор. Можно ли подключить VGA-кабелем с материнки телевизор, не будет конфликта?


VAS63> Вопрос от чайника:
VAS63> Хочу подключить вторым монитором телевизор. На ТВ есть VGA вход, на компе два выхода VGA на материнке и на видеокарте. К видеокарте подключен монитор. Можно ли подключить VGA-кабелем с материнки телевизор, не будет конфликта?
в целом можно (если у тебя винда типа XP или более новая) - это обычная двухмониторная конфигурация
VAS63> Хочу подключить вторым монитором телевизор. На ТВ есть VGA вход, на компе два выхода VGA на материнке и на видеокарте. К видеокарте подключен монитор. Можно ли подключить VGA-кабелем с материнки телевизор, не будет конфликта?
в целом можно (если у тебя винда типа XP или более новая) - это обычная двухмониторная конфигурация
Copyright © Balancer 1997..2024
Создано 01.01.1970
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
Создано 01.01.1970
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
